使用 LLM 给 Omnivore 上的文章进行自动摘要
背景
恰逢最近在整理自己的个人信息输入输出系统。在信息输入源上,借助 RSSHub 和 wewe-rss, 通过 RSS 订阅了一系列技术和互联网新闻媒体、微信公众号、独立博客以及 telegram channel 等,再结合 read it later 功能,这套组合基本上就满足了我的日常信息获取需求。于是挑战就转变成了找到一个趁手的 rss 阅读工具。
最初的尝试,自然是声名在外的 readwise reader,特别是新版的 readwise reader 支持自定义 prompt,能为每篇文章生成文章摘要,极大地方便了快速筛选和定位感兴趣的内容,避免标题党陷阱。我直接把之前会读上使用的那套 prompt 直接搬了过来(关于“会读”的技术实现回头也可以写篇博客讲讲)。这基本上实现了我一直想要的“理想的阅读器“ 形态,加上它与 notion 知识库的集成,使用体验很不错了。
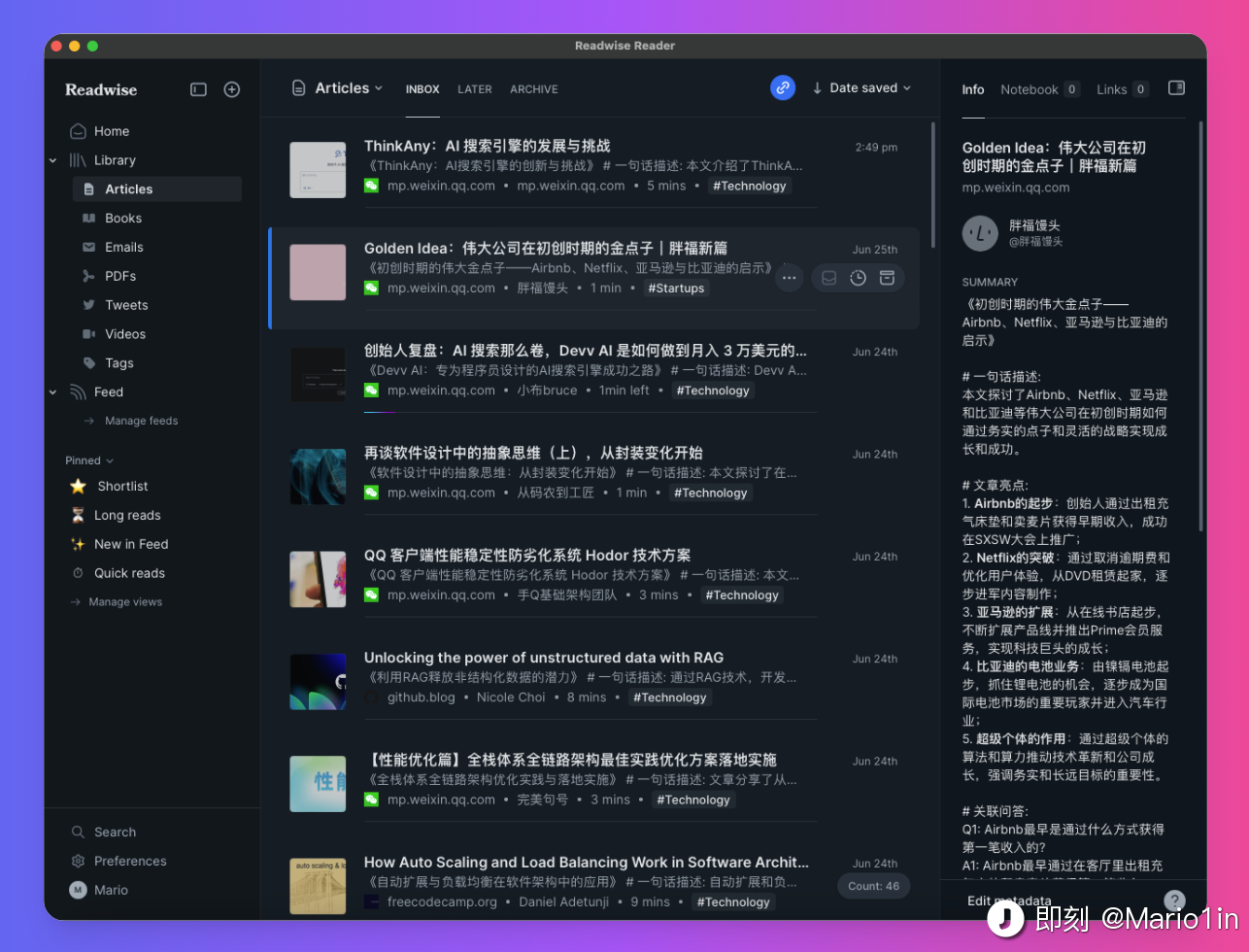
然而,某天,我偶然发现了一款名为 Omnivore 的稍后阅读软件。虽然它才刚起步不久,但已经具备了我在 readwise reader 上常用的大部分功能。更令人兴奋的是,它是开源的,支持本地部署,并且提供 api 和 webhook 能力,这简直给了我无限的可能(例如可以通过插件同步到 Obsidian 上)。最关键的是,它完全免费!(不得不说,readwise reader 着实是有点贵了..)
于是我花了点时间,把订阅迁移到了 Omnivore 上,并且使用官方提供的 chrome extension,可以快速保存网页文章供稍后阅读。但是,我最想念的还是 readwise reader 上那个基于 gpt + custom prompt 的文章摘要功能。不过,既然 Omnivore 提供了 api 和 webhook,那理论上也是可以做到的。
说干就干,我立刻着手开发。
核心代码:
首先,我们使用 fastapi,创建一个 webhook 接口,用于接收来自 Omnivore 的回调。通过判断 webhook_type ,我们可以确定触发此 webhook 的来源是什么。
@app.post("/")
async def webhook_handler(request: Request):
payload = await request.json()
label = payload.get("label")
page_created = payload.get("page")
if not payload:
raise HTTPException(status_code=400, detail="No payload found.")
webhook_type = None
if label and (label.get("labels") or label.get("name")):
webhook_type = "LABEL_ADDED"
elif page_created and page_created.get("id"):
webhook_type = "PAGE_CREATED"
article_id = None
if webhook_type == "LABEL_ADDED":
logger.info(f"========LABEL ADDED========")
logger.info(f"Label data: {label}")
annotate_label = os.getenv("OMNIVORE_ANNOTATE_LABEL", False)
if not annotate_label:
logger.error("No label specified in environment.")
raise HTTPException(status_code=400, detail="No label specified in environment.")
labels = label.get("labels") or [label]
label_names = [lbl.get("name") for lbl in labels]
if annotate_label not in label_names:
logger.error(f"Annotation label not found in label names: {label_names}")
raise HTTPException(status_code=400, detail="Not an annotation label")
article_id = label.get("pageId")
elif webhook_type == "PAGE_CREATED":
logger.info(f"========PAGE CREATED========")
logger.info(f"Page title: {page_created['title']}")
article_id = page_created.get("id")
else:
logger.warning("Neither label data received nor PAGE_CREATED event.")
raise HTTPException(status_code=400, detail="Neither label data received nor PAGE_CREATED event.")
if __name__ == "__main__":
import uvicorn
uvicorn.run(
app, host="0.0.0.0",
port=8080,
log_level="info",
reload=False
)
接下来,我们使用 OmnivoreQL 库,通过上述的 article_id 获取到文章内容。
def get_article_by_id(self, article_id: str):
article = self.client.get_article(self.username, article_id, format="markdown", include_content=True)
return article["article"]["article"]
def parse_article(self, article: dict):
aid = article["id"]
title = article["title"]
author = article["author"]
words_count = article["wordsCount"]
description = article["description"]
url = article["url"]
label_names = [label["name"] for label in article["labels"]]
label_ids = [label["id"] for label in article["labels"]]
omnivore_link = self.onmivore_link_template + article["slug"]
link_pattern = r"\[(.*?)\]\(.+?\)"
content = re.sub(link_pattern, r"\1", article["content"]) # removes links
content = re.sub(link_pattern, r"\1", content) # for nested links
logger.info(f"Processing article AID: {aid}")
logger.info(f"Title: {title}")
logger.info(f"Author: {author}")
logger.info(f"Current labels: {label_names}")
# logger.info(f"Description: {description}")
logger.info(f"Words count: {words_count}")
return aid, label_ids, title, content, omnivore_link, url
然后使用 GPT-4o 对文章内容进行摘要(此 prompt 非最终 prompt,可以根据自己的需要进行调整,如重新起个文章标题等):
class Summarizer:
def __init__(self):
self.prompt = os.getenv("OPENAI_PROMPT", """
你是一个作家,常擅长给文章写总结和推荐语。请你给下面文章写一句话的总结和推荐,表达出文章的核心内容,打开读者的好奇心。
输出的格式如下:
**总结:**
**推荐语:**
""")
self.model = os.getenv("OPENAI_MODEL", "gpt-4o")
self.api_key = os.getenv("OPENAI_API_KEY")
self.base_url = os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1")
logger.info(f"API Key: {self.api_key}, Base URL: {self.base_url}, Model: {self.model}")
self.client = OpenAI(api_key=self.api_key, base_url=self.base_url)
def get_summary(self, article_content: str):
try:
completion_response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": f"{self.prompt}\n"},
{
"role": "user",
"content": f"下面是文章内容: "
f"```" f"{article_content}\n"
f"```",
},
],
temperature=0
)
except Exception as e:
logger.error(f"Error fetching completion from OpenAI: {str(e)}")
raise e
return completion_response.choices[0].message.content.strip()
得到摘要内容后,我们便可以将它添加到文章对应的 notebook 里(没错,就是这么曲线救国):
def add_note_to_article(self, article_id: str, article_annotation: str):
id = str(uuid4())
short_id = id[:8]
mutation = gql("""
mutation CreateHighlight($input: CreateHighlightInput!) {
createHighlight(input: $input) {
... on CreateHighlightSuccess {
highlight {
id
type
shortId
quote
prefix
suffix
patch
color
annotation
createdByMe
createdAt
updatedAt
sharedAt
highlightPositionPercent
highlightPositionAnchorIndex
labels {
id
name
color
createdAt
}
}
}
... on CreateHighlightError {
errorCodes
}
}
}
""")
variables = {
"input": {
"type": "NOTE",
"id": id,
"shortId": short_id,
"articleId": article_id,
"annotation": article_annotation,
}
}
result = self.client.client.execute(mutation, variable_values=variables)
return result
最后,在 Omnivore 后台 Rules 里添加一条 Rule,filter=in:library, When=PAGE_CREATED,并将 webhook 地址设置为上述代码部署的 api 地址。
这样,我们便获得了和 readwise reader 一样的自动文章摘要能力了。
整体过程比较折腾,但在尝试不同的工具中也让我对信息管理有了新的理解。在实现的过程中,我会不断地询问自己:“我想要的到底是什么?”
只有深刻理解自己的需求,才能找到最适合自己的信息管理方式。